
The Next Moat
How to Build Defensible AI Products When Everyone Has Access to the Same Models

Midjourney
Why hasn't anyone made a better Midjourney? Lots of people have tried. ChatGPT, BlackForestLabs, Google. But you'll never get a committed Midjourney stan to switch.
What makes them so defensibly successful?
They've built a machine that distills professional creative judgment at scale.
Their community is filled with artists, illustrators, designers—people who've trained their whole lives to know good composition from bad. Take these users and put them in an environment that constantly forces and incentivizes them to make binary decisions (read: create great data) creates an advantage that is very hard to replicate, even as competitors match them technically. To create a better Midjourney, you would need to somehow recreate years of accumulated artistic taste.
Midjourney's defensibility against competitors with more resources, better models (including open source) teaches us a key lesson of competing in the AI era. Even as competitors innovate technically, the companies that will win, in the short and long run, will be the ones who can operationalize taste.
What Remains Defensible?
AI is getting more and more advanced, and can build and scale greenfield projects capably right now. It will only get better at this over time.
This means engineering quality and sophistication is less of a moat than it used to be. When building AI features, now, almost all frontier models are good enough to do most tasks that are useful for users, and everyone has access to the same set of models.
So how does anyone differentiate themselves?
Anyone can call an LLM API. Anyone can chain three prompts together. What they cannot copy overnight is knowing what good looks like in your domain—and operationalizing it.
This is trickier than it sounds because it's not enough to just know what's good—you have to truly, deeply understand what your customers want (including what they're not telling you, and would never tell you!).
The answer is to invest resources in what is hard to copy: defining and verifying taste.
The Bits that Are Hard to Copy
Expert annotations: data labeled by and conversations with experts where you gain much more clarity about exactly what you need to build.
Evaluator craftsmanship: the combination of rigor, expertise, and great engineering that lets you evaluate your outputs, evaluate your evaluators, and consistently improve.
Institutional memory: the implicit heuristics an organization develops by shipping many iterations and seeing what breaks in the real world.
Systems architecture: the design that allows each of these levers to be used to its fullest potential (there is often much, much, much more that you can get out of your data than you might realize).
Together, these form what I call Judgement Capital—a compounding, reusable asset that lets you consistently measure and enforce quality in ways your competitors simply can't copy.
This grows slowly, resists leakage, and amortizes over every feature—actively used and updated evaluators compound.
Measurement as Bottleneck
Any complex pipeline is bottlenecked by its hardest atomic subtask.
For an AI pipeline in a hard-to-verify domain, that subtask is often evaluating the output.
For example—say you created a validator with 80 % accuracy using a simple correctness metric. This validator limits you to shipping only what you can prove meets that bar. There is room for LLM variance to create incredible results using your pipeline, but you will only stumble across "incredible"—never reliably distinguish, reproduce, or guarantee it at scale. What you choose to measure—and how reliably you measure it—directly caps how good your product can become.
If all you check is correctness, or if you aim for merely "good enough," you can never tell if you're producing "great," "incredible," or "superhuman" outputs—they all look the same.
What You Measure, You Optimize
Benchmarks are saturating faster and faster.
The fastest way to improve performance in a given domain is to measure it—and you cannot improve what you cannot measure!
The chart below shows how fast benchmarks are saturating.
Note the trend: up and to the right.
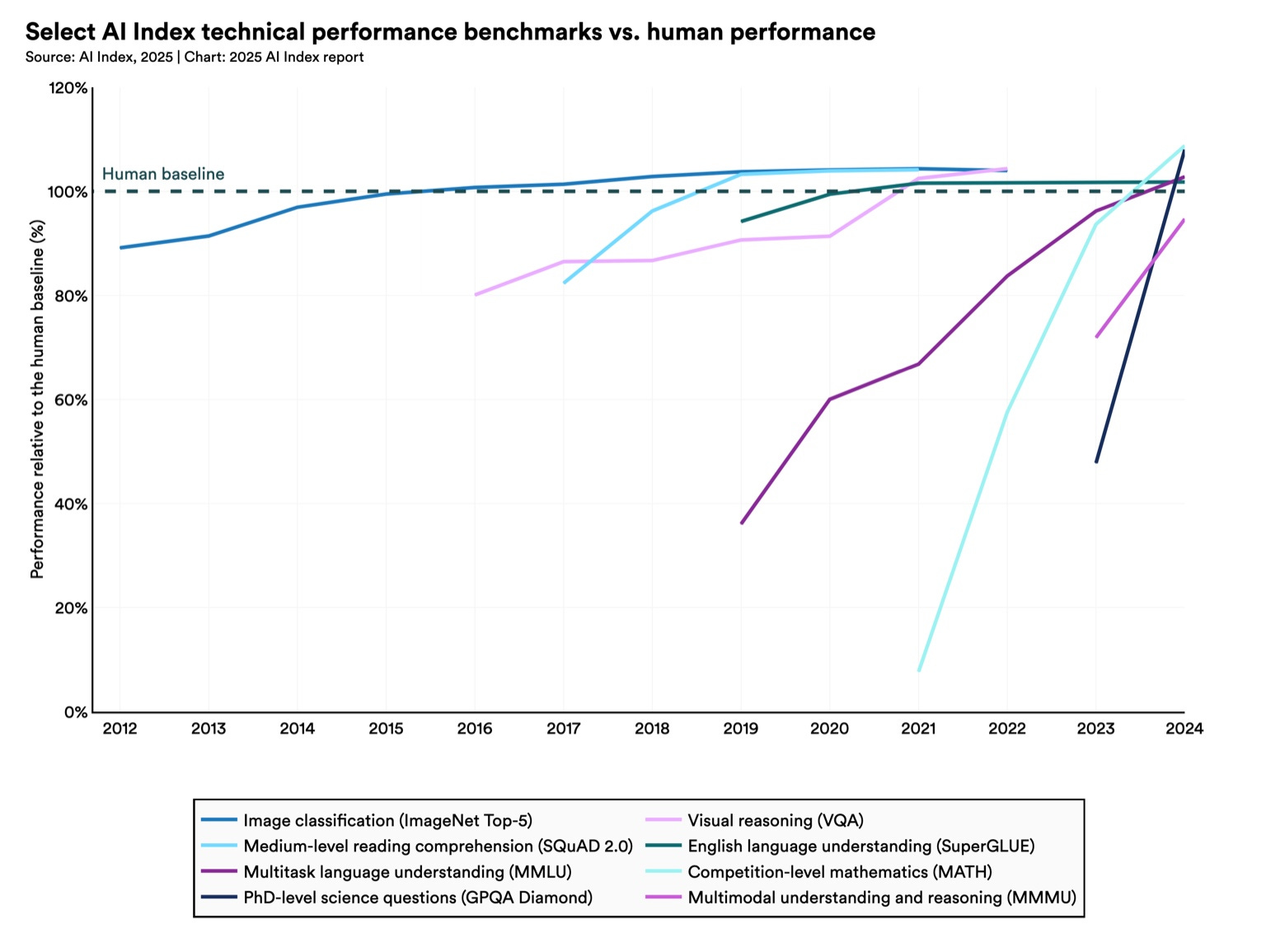
From this, I ask you to take away a very controversial idea: AI performance on clearly defined/measured tasks goes up and to the right.
LLMs and their engineers can make numbers go up. NVIDIA used a model in a loop to speed up CUDA kernels by 10–100%, AlphaEvolve broke a record by producing an entirely new algorithm for multiplying two 4x4 complex matrices, rescued 0.7% of Google's compute, and earlier this month, the Deep-Reinforce team published an RL training pipeline that enabled them to create a median speedup of 40% on KernelBench (for unseen kernels!). 1
Basically, it doesn't really matter what the objective is. If you can set up your problem as a Machine Learning problem, you can make your number go up.
Machine Learning Problems
A machine learning problem is one where there is training data, validation data to iterate with, a held-out testing set (to approximate real world performance) and one or more metrics to optimize.
This is how models are trained; it's an incredibly general formulation that lets you make number go up on any task you can define. You can only improve towards measurable signals.
I wrote this piece to urge you to treat your evaluation system as a machine learning problem. Give it at minimum an equal amount of time as your core AI feature.
A Brief Blueprint
When you start building AI systems, it's hard to evaluate them because there is a lot of data, you don't know what correct looks like, it's hard to be comprehensive, and you often can't one-shot (or even ten-shot) a prompt that properly evaluates your outputs.
Or maybe the generality of your system means you need ten different prompts and a classifier.
Maybe you just have 10 or 20 unversioned test cases that you rotate between and hand-judge when changing models.
So how do you start?
First, figure out what good looks like in your domain! This can come from your intuition for now. Think of just ONE thing that means you have a good output. The more concrete you can get it, the better, but it's okay if it's not super pinned down for now. It's very important to keep it binary. Don't be fooled into a 1–5 or percent-based score, it's much harder to calibrate. A binary score lets you leverage your fuzzy intuition that you've built up from working with your product closely.
Find some inputs and outputs. Score the outputs yourself—something as simple as is_good works.
Calibrate your rewards. Improve them. Watch your numbers go up.
The Compounding Advantage
If AI is part of your core value proposition and you want to leverage increasing model capabilities, spend at least as much time designing and building your system's judgement capital as you do the core product.
Here's why this investment compounds:
Better evaluators → Better outputs → More valuable data → Even better evaluators
Each model improvement multiplies against your evaluation infrastructure
Your competitors have to recreate years of accumulated taste from scratch
While they're stuck playing catch-up on generation quality, you're already optimizing for dimensions of quality they haven't even discovered yet.
Start Today
The best time to start building Judgement Capital was when you shipped your first AI feature. The second best time is now.
Start simple:
Pick one binary quality metric that matters to your users
Label 50–100 examples yourself
Build an evaluator
Watch your numbers go up
Remember: In a world where everyone can generate, only those who can verify will thrive.
Future Posts
This is part of an (at least) 4 part series on LLM engineering + Evals. The next post is about the user experience of AI engineering, how the default way of doing it leads to choosing local maximums that hurt you in the long run, and the one decision that gets you in a more high-quality and maintainable space for any LM feature from the start.
I really, really, really like DSPy (hint) and will be doing a lot of writing on that. I have lots typed up already, and I'm figuring out idea grouping and scoping.
My goal here is to show you how I think about AI Engineering problems—teach a man to fish type beat. There are ways of doing this that avoid a lot of pain you run into later down the line
Next Steps
If you found this valuable, it would mean a lot to me if you shared it with people you think would find it valuable too.
Also, I’m building a product based off of this philosophy! Click here: Testing MCPs